
I use Duckduckgo, but I realised these big(ish) search engines give me all the commercialised results. Duckduckgo has been going down the slope for years, but not at such a rate as Google or Bing has.
I want to have a search engine that gives me all the small blogs and personal sites.
Does something like this exist?
Don’t know if this fits your criteria, but I’ve been using Gruble a lot recently. You can personalise the look and language in the settings, plus it’s open source.
the link should be: https://gruble.de/. But as stated it’s “just” a SearXNG instance. See the full list: https://searx.space/
For info: That’s (just) a SearXNG instance. That’s a metasearch engine, getting results from Google etc and proxying and aggregating them for you.
You’re looking for Kagi.com
Not only does it give better search results quality wise on “the big web” - you can select to search specific parts, like blogs.
Best part - it’s completely ad and spam free. You pay for it with actual money instead of with your data.
Why not run an SearXNG instance and help everyone instead? Y’know, Kagi is pretty expensive and they are also getting into AI shit.
I’m hoping just as Proton do good free stuff using money I pay them (Visionary account) Kagi does/will do the same. The Internet as a whole needs to stop being ad-supported.
I refuse to believe Proton when they do advertisements lol. They also are being pretty suspicious with ignoring XMR support since years of people requesting it. If they ever even considered it a bit, their new shit Proton Wallet wouldn’t allow you to store (or only store) bitcoin, which we all know has nothing that protects your privacy.
Monero support is a massive red flag for criminal activity, even by the very low standards of crypto.
No. It’s for privacy. If they don’t support anonymous payments, there’s literally no reason to host a .onion site just to fool people. I’d say that’s a big red flag from a “privacy respecting” company.
There are pros/cons to anonymous payments. It’s a bit sophomoric to claim privacy is impossible without anonymous payments.
There are most definitely many use cases for .onion sites without any sort of payments (“anonymous” or otherwise).
The Internet as a whole needs to stop being ad-supported.
I’m with you to an extent but it also makes me consider what my online experience would have been if I needed money to do anything online. The internet was a huge part of my childhood and I definitely didn’t have money to spend on it.
We barely had enough to get internet when I was ~10yrs old and it was much later when we got something better than dial up.
I’ve signed up for the €5 a month subscription at kagi and I’ve never used my whole quota.
Granted I expect it’s overly expensive if you live in a developing country like Eritrea or the United States
5 euros a month for 300 searches. Definitely not worth it. I live in germany.
Like I say, I’ve never used all 300 because most of it is inane stuff that can still be googled
Though aye, if you’re rabidly searching for really specific furry porn, I can see it running out
Can you expand on how running your own SearXNG helps others? Does it contribute to some shared index or something?
SearXNG is a meta search engine, which means it gets the search results from other search engines (Google, Bing, Qwant, etc.) and show them to you. It acts a proxy, thus hiding the users IP. This means Google can’t target ads based on your IP and also can’t make a profile about you.
What IP is Google getting if I self host the instance?
The instance’s IP
Right. So, my IP. Which is the same (IP-wise) as if I’d just searched Google directly, leaving aside the benefits of searching other engines simultaneously.
I’ve also seen people suggest we should open our self-hosted SearXNG instances to others and let random people submit searches to it thereby causing searches to appear to come from my home IP address. That strikes me as a terrible idea given what some people search on the web. I have also never run a TOR exit node.
I use Kagi myself and I was hooked after using their free trial so I’m comparing to that.
When I submit a search to Kagi, Google (and their other downstream search engines) gets the search from Kagi. Yes, that means I have to trust Kagi to some extent but as we can see, there are obvious problems with SearXNG whether using it myself or opening it to others.
The AI features are mentioned further up the thread as a negative but I disagree. I recently cancelled my subscription to ChatGPT ($20/mo) and upgraded my Kagi subscription ($25/mo) which gives me searching and access to all the most popular LLMs which I do use from time to time, mostly for code help. Personally, it’s a great value.
I didn’t even know about the AI features when I started paying for it. That “side” of Kagi is fully optional and very unobtrusive.
That strikes me as a terrible idea given what some people search on the web. I have also never run a TOR exit node.
It is somewhat like a TOR exit node indeed. Though you can easily explain by saying that you did not make these searches but that you merely run a meta search engine that helps others protect their privacy. Even the TOR project has templates for exit nodes to submit them to the government or whoever is contacting them in those cases.
https://community.torproject.org/relay/community-resources/tor-abuse-templates/
That is exactly what I needed; the subdomains are now in my bookmarks.
Replying under the top comment but this really applies to all of these, how do these search engines determine what counts as a personal site? For example I had procrastinated for years on finally spinning up a static, barren HTML blog. The infamous Lucidity AI post introduced me to Mataroa and I got over the hump and started writing. Would that get indexed? Etc
Does it just crawl through webrings?
I believe you have to submit your own website to this one for manual addition to its index
I’m intrigued. The search results are more akin to how they used to be 25 years ago on the internet that I loved
Https://Search.marginalia.nu is dinitely something I’ll be exploring going forward!I searched for Dance Dance Revolution and ended up here.
The absolute nostalgia of it all. Love it.
Maybe try Mojeek, it uses completely independent indexing system.
Mojeek
Thanks for the rec, I’ll give Mojeek a try for a while. So far the results seem better than Brave (which I didn’t seriously consider using regularly anyway) but I miss the bang options (!w, !yt, etc.) that DDG has.
our Search Choices might be of use here, different implementation but similar: https://blog.mojeek.com/2022/02/search-choices-enable-freedom-to-seek.html
our Search Choices might be of use here
Thanks, I think that’s a valuable option! It’s probably not what I was looking for. As I understand it, the “bang” use is just a way to use the search on a specific webpage, and is just a nice little hack to speed up searches on commonly used websites (i.e., Wikipedia, YouTube, BBC, etc.) I can probably get used to going straight to those sites, but it was a feature that got me using DDG at first and broke my reliance on Google.
Choices do this very thing, you click a button and the search in the bar goes to that site, if you have this enabled in the search bar. If not they are present at the bottom of the results.
We are in the process of open sourcing the library of choices so they are user-submitted.
Teclis - Includes search results from Marginalia, free to use at the moment. This search index has been in the past closed down due to abuse.
Kagi, whose creation Teclis is, is a paid search engine (metasearch engine to be more precise) also incorporates these search results in their normal searches. I warmly recommend giving Kagi a try, it’s great, I’ve been enjoying it a lot.
–
Other options I can recommend; You could always try to host your own search engine if you have list of small-web sites in mind or don’t mind spending some effort collecting such list. I personally host Yacy [github link] (and Searxng to interface with yacy and several other self-hosted indexes/search engines such as kiwix wiki’s.). Indexing and crawling your own search results surprisingly is not resource heavy at all, and can be run on your personal machine in the background.
Not just a meta search engine though - they do have their own index as well.
https://help.kagi.com/kagi/search-details/search-sources.html
Yes, I mentioned Kagi because of the Teclis search index is hosted by them.
However, most of the search results in Kagi are aggregated from dedicated search engines. (such as, but not limited to: Yandex, Brave, Google, Bing, etc.)
I tried running yacy for a while but it just ran for a bit less than a day then ran out of memory and crashed, over and over. Tried to figure out the problem, but it’s niche enough that I couldn’t get anywhere googling the issue.
This is a bit off-topic, but did you try to increase the JVM limits inside Yacy’s administration panel?
Spoilering to hide wall of text related to this topic.
This setting located in
/Performance_p.html-page for example gives the java runtime more memory. Same page also has other settings related to ram, such as setting how much memory Yacy must leave unused for the system. (These settings exist so people who run Yacy on their personal machines can have guaranteed resources for more important stuff)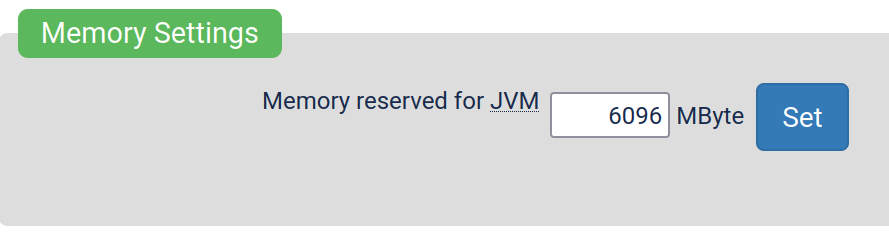
Other things that would reduce memory usage is to limit the concurrency of the crawler for example. There’s quite a lot of tunable settings that can affect memory usage. Would recommend trying to hit up one of the Yacy forums is also good place to ask questions. The Matrix channel (and IRC) are a bit dead, but there are couple of people including myself there!
Also, theres new docs written by the community, they might help as well! https://yacy.net/docs/ https://yacy.net/operation/performance/
Yeah, I did try that. Basically, if I doubled the memory I allocated, I gave it half again longer before it crashed, but it still crashed, eventually.
It’s no big deal, this was last year, I may try again one day. Loving Searxng though!
Personally really been enjoying Kagi for the past year.
This is a great question, in that it made me wonder why the Fediverse hasn’t come up with a distributed search engine yet. I can see the general shape of a system, and it’d require some novel solutions to keep it scalable while still allowing reasonably complex queries. The biggest problems with search engines is that they’re all scanning the entire internet and generating a huge percent of all internet traffic; they’re all creating their own indexes, which is computationally expensive; their indexes are huge, which is space-expensive; and quality query results require a fair amount of computing resources.
A distributed search engine, with something like a DHT for the index, with partitioning and replication, and a moderation system to control bad actors and trojan nodes. DDG and SearX are sort of front ends for a system like this, except that they just hand off the queries to one (or two) of the big monolithic engines.
We’d love to build a distributed search engine, but it would be too slow I think. When you send us a query we go and search 8 billion+ pages, and bring back the top 10, 20…up to 1,000 results. For a good service we need to do that in 200ms, and thus one needs to centralise the index. It took years, several iterations and our carefully designed algos & architecture to make something so fast. No doubt Google, Bing, Yandex & Baidu went through similar hoops. Maybe, I’m wrong and/or someone can make it work with our API.
I think 200ms is an expectation of big tech. I know people have very little patience these days, but if you provided better quality searches in 5 seconds people would probably prefer that over a .2 second response of the crap we’re currently getting from the big guys. Even better if you can make the wait a little fun with some animations, public domain art, or quotes to read while waiting.
if you provided better quality searches in 5 seconds people would probably prefer that over a .2 second response of the crap we’re currently getting from the big guys
This is precisely what made me switch to ChatGPT as my primary “search engine”. Even DDG is fucking useless these days if you need anything more complex than a list of popular sites that contain a couple of keywords.
I thought Gigablast was a one-man company? Yet it had good search results and it was expansive.
Yes, it was. Matt Wells closed it down just over one year ago.
YaCy is probably what you’re looking for
Yah, it does. I’ve come across it before, but it rode in on a wave of alternative search engines and got lost in the shuffle.
Thanks.
Before google existed I used https://www.metacrawler.com it appears to still be around. I have not used it in a long time, so I know nothing about it any longer.
https://system1.com/ adtech company syndicating Bing and/or Google
https://system1.com/ adtech company syndicating Bing and/or Google
They own metacrawler now?
yep, in footer “© 2024 Infospace Holdings LLC, A System1 Company”
Offtopic but ddg is a bing frontend so they should share the same results.
Google are the ones who have really gone down the toilet in recent years. They ditched cached pages, soured search results with paid ads and even their image search is as bad as Tineye for reverse image searching these days. Literally the only thing Alphabet really have going for them anymore is Android and YouTube.
It’s baffling that a company which was once so dominant in the web search space that their name was literally used as a verb for looking things up for decades have now enshittified their flagship product so much that they’re making rivals like Bing, Lycos, Duckduckgo, etc look like viable alternatives.
Every company is going down the drain just at different speeds.
If you want blogs, I recommend you use gemini: https://en.wikipedia.org/wiki/Gemini_(protocol)
Download Lagrange and begin browsing. It’s basically a small-web of personal blogs.
it’s of course great! But not really an alternative to the current web search engine… Do you have a search engine for Gemini?
gemini://kennedy.gemi.dev/
The more obscure a web page is, the more likely it is to be indexed only by the large search engines (i.e. Google). There are search queries that return 0 results on DDG, but quite a few (relatively) obscure websites on Google. This is simply because the more money a search engine operator has, the more websites it will index.
So what you want is kind of contradictory.
Although Google indeed is the greatest indexer of the World Wide Web, unfortunately, the SEO and the AI makes it so hard to find something, for example, from before 2000s, such as BBS List archives, old blogosphere and personal webpages from that time, simply because they had no modern SEO nor AI keywords at that time. These old content are entirely free from AI-generated slop, (almost) free from dis- and mis-informations (because, at the time of BBS and Gopher, the Internet was still being born, and books were the main source of knowledge), so old content is sine qua non for one that’s seeking real knowledge.
(almost) free from dis- and mis-informations (because, at the time of BBS and Gopher, the Internet was still being born
Yeah, no. There was tons of bullshit. I ran across a post back then saying you could get psychic powers by eating the Americium sensor in your fire detector.
Try this engine
Or a SearXNG instance
https://search.disroot.org/search
You may also be interested in the Indie Web movement. This site is a great resource for it, with yet more links to indie sites and blogs.
Finally, not quite what you asked but here’s a freebie, in case you didn’t know about it:
It’s an old web search engine. It only indexes pages from the 00s and earlier.
Ah Marginalia is absolutely awesome! I feel like modern search is almost an extension of website names now, so if I want to find netflix but don’t know it’s website, I might search for “netflix”. Marginalia is actually a cool way to find new stuff- like you can search “bike maintenance” and find cool blog posts about that topic.
I honestly can’t remember if that’s something google and the like used to do, but doesn’t now, or if they never did. Either way, I love it!
This is how Google started out, until like 2010-2015 it was wonderful. I think it’s just losing the seo slop arms race now tbh
Aside from SearXNG, I didn’t know about these search engines until your recommendation. Thanks to Wiby and Marginalia, I found old rich content (old BBS list conversations, for example) that I was looking for, regarding studies on the occult and esotericism. Thank you so much!
I’m building my own. Keep you posted.
I make one for web dev and mastodon.
You can’t just index mastodon, they’ll kill you!
Im a grown up, I have self preservation instincts. Only indexing opt in accounts and only for limited time so the angry mob won’t burn me.













