
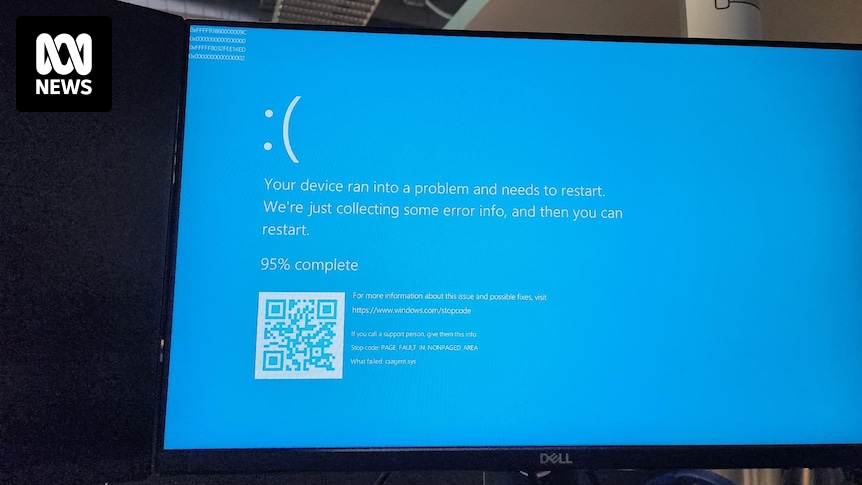
All our servers and company laptops went down at pretty much the same time. Laptops have been bootlooping to blue screen of death. It’s all very exciting, personally, as someone not responsible for fixing it.
Apparently caused by a bad CrowdStrike update.
Edit: now being told we (who almost all generally work from home) need to come into the office Monday as they can only apply the fix in-person. We’ll see if that changes over the weekend…
I mean I know it’s easy to be critical but this was my exact thought, how the hell didn’t they catch this in testing?
Completely justified reaction. A lot of the time tech companies and IT staff get shit for stuff that, in practice, can be really hard to detect before it happens. There are all kinds of issues that can arise in production that you just can’t test for.
But this… This has no justification. A issue this immediate, this widespread, would have instantly been caught with even the most basic of testing. The fact that it wasn’t raises massive questions about the safety and security of Crowdstrike’s internal processes.
“I ran the update and now shit’s proper fucked”
That would have been sufficient to notice this update’s borked
I think when you are this big you need to roll out any updates slowly. Checking along the way they all is good.
The failure here is much more fundamental than that. This isn’t a “no way we could have found this before we went to prod” issue, this is a “five minutes in the lab would have picked it up” issue. We’re not talking about some kind of “Doesn’t print on Tuesdays” kind of problem that’s hard to reproduce or depends on conditions that are hard to replicate in internal testing, which is normally how this sort of thing escapes containment. In this case the entire repro is “Step 1: Push update to any Windows machine. Step 2: THERE IS NO STEP 2”
There’s absolutely no reason this should ever have affected even one single computer outside of Crowdstrike’s test environment, with or without a staged rollout.
God damn this is worse than I thought… This raises further questions… Was there a NO testing at all??
My guess is they did testing but the build they tested was not the build released to customers. That could have been because of poor deployment and testing practices, or it could have been malicious.
Such software would be a juicy target for bad actors.
Yes. And Microsoft’s
How exactly is Microsoft responsible for this? It’s a kernel level driver that intercepts system calls, and the software updated itself.
This software was crashing Linux distros last month too, but that didn’t make headlines because it effected less machines.
From what I’ve heard, didn’t the issue happen not solely because of CS driver, but because of a MS update that was rolled out at the same time, and the changes the update made caused the CS driver to go haywire? If that’s the case, there’s not much MS or CS could have done to test it beforehand, especially if both updates rolled out at around the same time.
I’ve seen zero suggestion of this in any reporting about the issue. Not saying you’re wrong, but you’re definitely going to need to find some sources.
Is there any links to this?
From what I’ve heard and to play a devil’s advocate, it coincidented with Microsoft pushing out a security update at basically the same time, that caused the issue. So it’s possible that they didn’t have a way how to test it properly, because they didn’t have the update at hand before it rolled out. So, the fault wasn’t only in a bug in the CS driver, but in the driver interaction with the new win update - which they didn’t have.
How sure are you about that? Microsoft very dependably releases updates on the second Tuesday of the month, and their release notes show if updates are pushed out of schedule. Their last update was on schedule, July 9th.
I’m not. I vaguely remember seeing it in some posts and comments, and it would explain it pretty well, so I kind of took it as a likely outcome. In hindsight, You are right, I shouldnt have been spreading hearsay. Thanks for the wakeup call, honestly!
I have had numerous managers tell me there was no time for QA in my storied career. Or documentation. Or backups. Or redundancy. And so on.
Push that into the technical debt. Then afterwards never pay off the technical debt
Move fast and break things! We need things NOW NOW NOW!
Just always make sure you have some evidence of them telling you to skip these.
There’s a reason I still use lots of email in the age of IM. Permanent records, please. I will email a record of in person convos or chats on stuff like this. I do it politely and professionally, but I do it.
A lot of people really need to get into the habit of doing this.
“Per our phone conversation earlier, my understanding is that you would like me to deploy the new update without any QA testing. As this may potentially create significant risks for our customers, I just want to confirm that I have correctly understood your instructions before proceeding.”
If they try to call you back and give the instruction over the phone, then just be polite and request that they reply to your email with their confirmation. If they refuse, say “Respectfully, if you don’t feel comfortable giving me this direction in writing, then I don’t feel comfortable doing it,” and then resend your email but this time loop in HR and legal (if you’ve ever actually reached this point, it’s basically down to either them getting rightfully dismissed, or you getting wrongfully dismissed, with receipts).
Engineering prof in uni was big on journals/log books for cyoa and it’s stuck with me, I write down everything I do during the day, research, findings etc, easily the best bit of advice I ever had.
Unless their manager works in Boeing.
There’s some holes in our production units
Software holes, right?
…
…software holes, right?