It is not. It is designed for all purposes, automated processes and people alike. A filesystem is not just for grandma’s Word documents.
And even people’s names are case sensitive. My name has the format Aaa Bbb ccc Ddd. It is not the same as the person with the name Aaa Bbb Ccc Ddd, who also exists. So why shouldn’t file names be?
Anyway, even for those automated processes, there’s no good reason to use files with the same names in the same directory, it’s bad practice and adds unnecessary confusion in the design of the code.
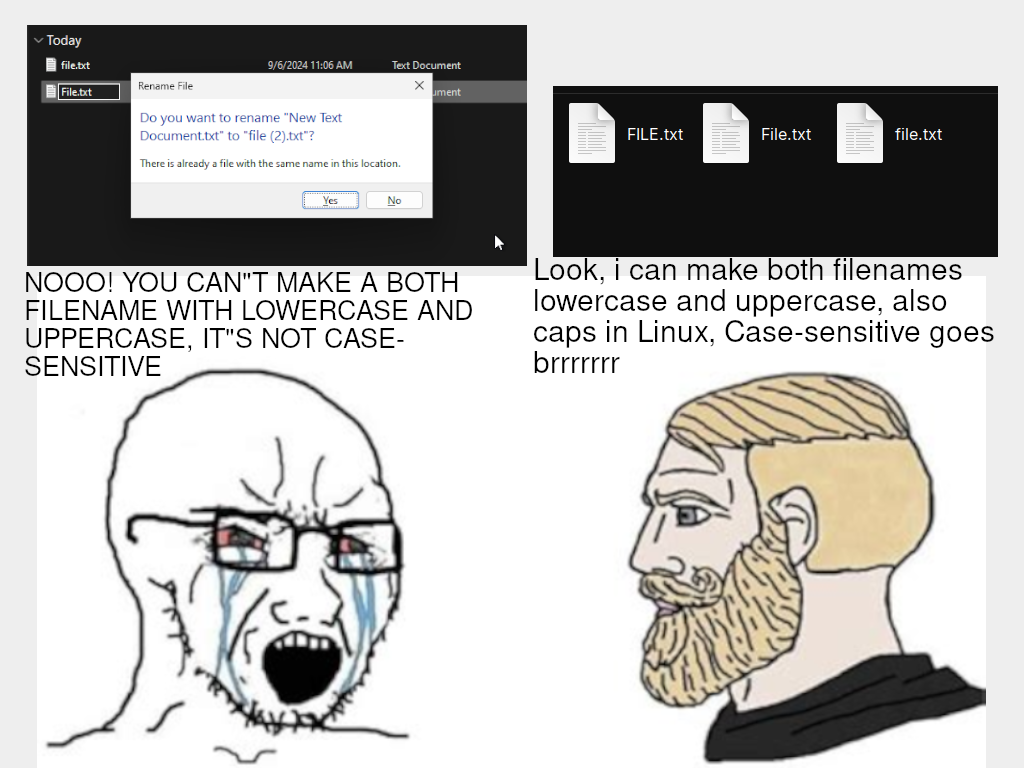
give me one use case where it makes sense having several files with the same name but different cases in the same directory
Imagine a table in a database where the primary key is a case sensitive character field, because you know varchars, just like C char types and string types in other languages are case sensitive.
Imagine a database administrator does the following:
Export all data with primary key = ‘Abcde’ to ‘Abcde.csv’
Imagine a second database adminstrator around the same time does the following:
Export all data with primary key = ‘abcde’ to ‘abcde.csv’
Now imagine this is the GDPR data of two different users.
If you have a case insensitive file system, you’ve just overwritten something you shouldn’t have and possibly even leaked confidential data.
If you have a case sensitive file system you don’t have to account for this scenario. If the PK is unique, the filename will be unique, end of story.
The point is you have to take this into account, so the decision to go with a case insensitive file system has ripple effects much further down your system. You have to design around it at every step in code where a string variable results in a file being written to or read from.
It’s much more elegant if you can simply assume that a particular string will 1-on-1 match with a unique filename.
Even Microsoft understands this btw, their Azure Blob Storage system is case sensitive. The only reason NTFS isn’t (by default) is because of legacy. It had to be compatible with all uppercase 8.3 filenames from DOS/FAT16.


{kind=link}
It is not. It is designed for all purposes, automated processes and people alike. A filesystem is not just for grandma’s Word documents.
And even people’s names are case sensitive. My name has the format Aaa Bbb ccc Ddd. It is not the same as the person with the name Aaa Bbb Ccc Ddd, who also exists. So why shouldn’t file names be?
Different words that say the same thing…
Anyway, even for those automated processes, there’s no good reason to use files with the same names in the same directory, it’s bad practice and adds unnecessary confusion in the design of the code.
Imagine a table in a database where the primary key is a case sensitive character field, because you know varchars, just like C char types and string types in other languages are case sensitive.
Imagine a database administrator does the following:
Imagine a second database adminstrator around the same time does the following:
Now imagine this is the GDPR data of two different users.
If you have a case insensitive file system, you’ve just overwritten something you shouldn’t have and possibly even leaked confidential data.
If you have a case sensitive file system you don’t have to account for this scenario. If the PK is unique, the filename will be unique, end of story.
If you don’t do something stupid like reuse keys just with different capitalization, this never occurs.
The point is you have to take this into account, so the decision to go with a case insensitive file system has ripple effects much further down your system. You have to design around it at every step in code where a string variable results in a file being written to or read from.
It’s much more elegant if you can simply assume that a particular string will 1-on-1 match with a unique filename.
Even Microsoft understands this btw, their Azure Blob Storage system is case sensitive. The only reason NTFS isn’t (by default) is because of legacy. It had to be compatible with all uppercase 8.3 filenames from DOS/FAT16.