
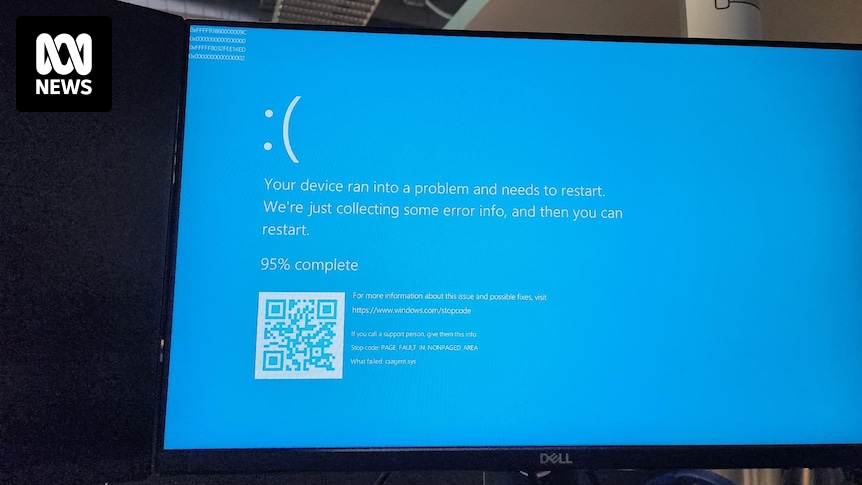
All our servers and company laptops went down at pretty much the same time. Laptops have been bootlooping to blue screen of death. It’s all very exciting, personally, as someone not responsible for fixing it.
Apparently caused by a bad CrowdStrike update.
Edit: now being told we (who almost all generally work from home) need to come into the office Monday as they can only apply the fix in-person. We’ll see if that changes over the weekend…
This is a a ruse to make Work From Home end.
All IT people should go on general strike now.
Irrelevant but I keep reading “crowd strike” as “counter strike” and it’s really messing with me
I picked the right week to be on PTO hahaha
It’s Russia, or Iran or China or even our “ally” Saudi Arabia. So really, it’s time to reset the clock to pre 1989. Cut Russia and China off completely, no investment, no internet, no students no tourist nothing. These people mean and are continually doing us harm and we still plod along and some unscrupulous types become agents for personal profit. Enough.
No one bother to test before deploying to all machines? Nice move.
This outage is probably costing a significant portion of Crowd strike’s market cap. They’re an 80 billion dollar company but this is a multibillion outage.
Someone’s getting fired for this. Massive process failures like this means that it should be some high level managers or the CTO going out.
Puts on Crowdstrike?
They’re already down ~9% today:
https://finance.yahoo.com/quote/CRWD/
So I think you’re late to the party for puts. Smart money IMO is on a call for a rebound at this point. Perhaps smarter money is looking through companies that may have been overlooked that would be CrowdStrike customers and putting puts on them. The obvious players are airlines, but there could be a ton of smaller cap stocks that outsource their IT to them, like regional trains and whatnot.
Regardless, I don’t gamble w/ options, so I’m staying out. I could probably find a deal, but I have a day job to get to with nearly 100% odds of getting paid.
~20% down in the last month
52 Week Range 140.52 - 398.33
They’re about where they were back in early June. If they weather this, I don’t see a reason why they wouldn’t jump back to their all-time high in late June. This isn’t a fundamental problem with the solution, it’s a hiccup that, if they can recover quickly, will be just a blip like there was in early June.
I think it’ll get hammered a little more today, and if the response looks good over the weekend, we could see a bump next week. It all depends on how they handle this fiasco this weekend.
Nice. The first comment is basically saying, “they’re best in class, so they’re worth the premium.” And then the general, “you’ll probably do better by doing the opposite of /r/wallstreetbets” wisdom.
So yeah, if I wanted to gamble, I’d be buying calls for a week or so out when everyone realizes that the recovery was relatively quick and CrowdStrike is still best in class and retained its customers. I think that’s the most likely result here. Switching is expensive for companies like this, and the alternatives aren’t nearly as good.
YOLO 🚀🙈
play stupid games win stupid prizes
This is why you create restore points if using windows.
This is the best summary I could come up with:
There are reports of IT outages affecting major institutions in Australia and internationally.
The ABC is experiencing a major network outage, along with several other media outlets.
Crowd-sourced website Downdetector is listing outages for Foxtel, National Australia Bank and Bendigo Bank.
Follow our live blog as we bring you the latest updates.
The original article contains 52 words, the summary contains 52 words. Saved 0%. I’m a bot and I’m open source!
The original article contains 52 words, the summary contains 52 words. Saved 0%.
Good bot!
This is going to be a Big Deal for a whole lot of people. I don’t know all the companies and industries that use Crowdstrike but I might guess it will result in airline delays, banking outages, and hospital computer systems failing. Hopefully nobody gets hurt because of it.
Big chunk of New Zealands banks apparently run it, cos 3 of the big ones can’t do credit card transactions right now
cos 3 of the big ones can’t do credit card transactions right now
Bitcoin still up and running perhaps people can use that
It was mayhem at PakNSave a bit ago.
In my experience it’s always mayhem at PakNSave.
If anything, it’s probably calmed P’n’S down a bit…
Huh. I guess this explains why the monitor outside of my flight gate tonight started BSoD looping. And may also explain why my flight was delayed by an additional hour and a half…
Reading into the updates some more… I’m starting to think this might just destroy CloudStrike as a company altogether. Between the mountain of lawsuits almost certainly incoming and the total destruction of any public trust in the company, I don’t see how they survive this. Just absolutely catastrophic on all fronts.
Don’t we blame MS at least as much? How does MS let an update like this push through their Windows Update system? How does an application update make the whole OS unable to boot? Blue screens on Windows have been around for decades, why don’t we have a better recovery system?
This didn’t go through Windows Update. It went through the ctowdstrike software directly.
Crowdstrike runs at ring 0, effectively as part of the kernel. Like a device driver. There are no safeguards at that level. Extreme testing and diligence is required, because these are the consequences for getting it wrong. This is entirely on crowdstrike.
Agreed, this will probably kill them over the next few years unless they can really magic up something.
They probably don’t get sued - their contracts will have indemnity clauses against exactly this kind of thing, so unless they seriously misrepresented what their product does, this probably isn’t a contract breach.
If you are running crowdstrike, it’s probably because you have some regulatory obligations and an auditor to appease - you aren’t going to be able to just turn it off overnight, but I’m sure there are going to be some pretty awkward meetings when it comes to contract renewals in the next year, and I can’t imagine them seeing much growth
Don’t most indemnity clauses have exceptions for gross negligence? Pushing out an update this destructive without it getting caught by any quality control checks sure seems grossly negligent.
Nah. This has happened with every major corporate antivirus product. Multiple times. And the top IT people advising on purchasing decisions know this.
Yep. This is just uninformed people thinking this doesn’t happen. It’s been happening since av was born. It’s not new and this will not kill CS they’re still king.
At my old shop we still had people giving money to checkpoint and splunk, despite numerous problems and a huge cost, because they had favourites.
deleted by creator
Was it not possible for MS to design their safe mode to still “work” when Bitlocker was enabled? Seems strange.
I’m not sure what you’d expect to be able to do in a safe mode with no disk access.
Why is it bad to do on a Friday? Based on your last paragraph, I would have thought Friday is probably the best week day to do it.
deleted by creator
And hence the term read-only Friday.
Most companies, money included, try to roll out updates during the middle of start of a week. That way if there are issues the full team is available to address them.
explain to the project manager with crayons why you shouldn’t do this
Can’t; the project manager ate all the crayons
Testing is production will do that
Not everyone is fortunate enough to have a seperate testing environment, you know? Manglement has to cut cost somewhere.
Manglement is the good term lmao
I think you’re on the nose, here. I laughed at the headline, but the more I read the more I see how fucked they are. Airlines. Industrial plants. Fucking governments. This one is big in a way that will likely get used as a case study.
The London Stock Exchange went down. They’re fukd.
Yeah saw that several steel mills have been bricked by this, that’s months and millions to restart
Got a link? I find it hard to believe that a process like that would stop because of a few windows machines not booting.
There are a lot of heavy manufacturing tools that are controlled and have their interface handled by Windows under the hood.
They’re not all networked, and some are super old, but a more modernized facility could easily be using a more modern version of Windows and be networked to have flow of materials, etc more tightly integrated into their systems.
The higher precision your operation, the more useful having much more advanced logs, networked to a central system, becomes in tracking quality control. Imagine after the fact, you can track some .1% of batches that are failing more often and look at the per second logs of temperature they were at during the process, and see that there’s 1° temperature variance between the 30th to 40th minute that wasn’t experience by the rest of your batches. (Obviously that’s nonsense because I don’t know anything about the actual process of steel manufacturing. But I do know that there’s a lot of industrial manufacturing tooling that’s an application on top of windows, and the higher precision your output needs to be, the more useful it is to have high quality data every step of the way.)
a few windows machines with controller application installed
That’s the real kicker.
Those machines should be airgapped and no need to run Crowdstrike on them. If the process controller machines of a steel mill are connected to the internet and installing auto updates then there really is no hope for this world.
But daddy microshoft says i gotta connect the system to the internet uwu
No, regulatory auditors have boxes that need checking, regardless of the reality of the technical infrastructure.
I work in an environment where the workstations aren’t on the Internet there’s a separate network, there’s still a need for antivirus and we were hit with bsod yesterday
If all the computers stuck in boot loop can’t be recovered… yeah, that’s a lot of cost for a lot of businesses. Add to that all the immediate impact of missed flights and who knows what happening at the hospitals. Nightmare scenario if you’re responsible for it.
This sort of thing is exactly why you push updates to groups in stages, not to everything all at once.
Looks like the laptops are able to be recovered with a bit of finagling, so fortunately they haven’t bricked everything.
And yeah staged updates or even just… some testing? Not sure how this one slipped through.
One of my coworkers, while waiting on hold for 3+ hours with our company’s outsourced helpdesk, noticed after booting into safe mode that the Crowdstrike update had triggered a snapshot that she was able to roll back to and get back on her laptop. So at least that’s a potential solution.
Not sure how this one slipped through.
I’d bet my ass this was caused by terrible practices brought on by suits demanding more “efficient” releases.
“Why do we do so much testing before releases? Have we ever had any problems before? We’re wasting so much time that I might not even be able to buy another yacht this year”
At least nothing like this happens in the airline industry
Certainly not! Or other industries for that matter. It’s a good thing executives everywhere aren’t just concentrating on squeezing the maximum amount of money out of their companies and funneling it to themselves and their buddies on the board.
Sure, let’s “rightsize” the company by firing 20% of our workforce (but not management!) and raise prices 30%, and demand that the remaining employees maintain productivity at the level it used to be before we fucked things up. Oh and no raises for the plebs, we can’t afford it. Maybe a pizza party? One slice per employee though.
What lawsuits do you think are going to happen?
Forget lawsuits, they’re going to be in front of congress for this one
For what? At best it would be a hearing on the challenges of national security with industry.
They can have all the clauses they like but pulling something like this off requires a certain amount of gross negligence that they can almost certainly be held liable for.
Whatever you say my man. It’s not like they go through very specific SLA conversations and negotiations to cover this or anything like that.
I forgot that only people you have agreements with can sue you. This is why Boeing hasn’t been sued once recently for their own criminal negligence.
👌👍
Yep, stuck at the airport currently. All flights grounded. All major grocery store chains and banks also impacted. Bad day to be a crowdstrike employee!
My flight was canceled. Luckily that was a partner airline. My actual airline rebooked me on a direct flight. Leaves 3 hours later and arrives earlier. Lower carbon footprint. So, except that I’m standing in queue so someone can inspect my documents it’s basically a win for me. 😆
My work PC is affected. Nice!
Same! Got to log off early 😎
Noice!
Plot twist: you’re head of IT
Dammit, hit us at 5pm on Friday in NZ
4:00PM here in Aus. Absolutely perfect for an early Friday knockoff.
If these affected systems are boot looping, how will they be fixed? Reinstall?
There is a fix people have found which requires manual booting into safe mode and removal of a file causing the BSODs. No clue if/how they are going to implement a fix remotely when the affected machines can’t even boot.
Do you have any source on this?
It seems like it’s in like half of the news stories.
I can confirm it works after applying it to >100 servers :/
Nice work, friend. 🤝 [back pat]
If you have an account you can view the support thread here: https://supportportal.crowdstrike.com/s/article/Tech-Alert-Windows-crashes-related-to-Falcon-Sensor-2024-07-19
Workaround Steps:
-
Boot Windows into Safe Mode or the Windows Recovery Environment
-
Navigate to the C:\Windows\System32\drivers\CrowdStrike directory
-
Locate the file matching “C-00000291*.sys”, and delete it.
-
Boot the host normally.
-
Probably have to go old-skool and actually be at the machine.
Exactly, and super fun when all your systems are remote!!!
It’s not super awful as long as everything is virtual. It’s annoying, but not painful like it would be for physical systems.
Really don’t envy physical/desk side support folks today…
And hope you are not using BitLocker cause then you are screwed since BitLocker is tied to CS.
You just need console access. Which if any of the affected servers are VMs, you’ll have.
Yes, VMs will be more manageable.
It is possible to edit a folder name in windows drivers. But for IT departments that could be more work than a reimage
Having had to fix >100 machines today, I’m not sure how a reimage would be less work. Restoring from backups maybe, but reimage and reconfig is so painful
It’s just one file to delete.
My dad needed a CT scan this evening and the local ER’s system for reading the images was down. So they sent him via ambulance to a different hospital 40 miles away. Now I’m reading tonight that CrowdStrike may be to blame.














